Protecting Privacy in Recorded
Conversations
The purpose of this project is to develop a scientific workflow that protects the privacy of individuals and entities in recorded conversations. This project was initiated by the Computer Science Master’s Degree Thesis authored by Scot Cunningham, a 2007 graduate student at Northern Kentucky University (www.nku.edu), under the advice of Dr. Traian Marius Truta, Assistant Professor of Computer Science at NKU. The full text of this thesis can be found here. Scot Cunningham is also a Senior Manager at Convergys Corporation. Scot's homepage can be found here.
The Privrec scientific workflow integrates
well-known data privacy techniques with custom distortion techniques to
identify and distort sensitive audio while at the same time maintaining minimal
data loss in both contextual content and audio signal characteristics. The intended outcome of this research is to enable
corpora that contain sensitive audio recordings and their associated
transcriptions to be shared between various business and academic entities for
purposes of research and development as well as for the improvement of applications
that make use of speech technology.
These audio examples demonstrate the results of the distortion techniques on an audio file. Only the word “Chicago” is distorted. Note that the intent here was to distort the audio so that an automatic recognizer is incapable of interpreting the selected audio segment. In some cases, the distortion needed to thwart the recognizer resulted in audio that is still easily discernable to human ears as is evident by the following example:
Distortion intended to thwart human recognition is an area of further study. Human intelligibility of encrypted speech using various techniques has been an area of study for decades. In “A Comparison of Four Methods for Analog Speech Privacy” (IEEE Transactions on Communications, Volume 29, Issue 1, Jan 1981 pp. 18 - 23), several techniques for speech encryption are compared for their ability to thwart human intelligibility. The results of three of these techniques on our audio samples are provided below.
![]() Frequency
Inversion Plus Block Permutation
Frequency
Inversion Plus Block Permutation
Although these techniques distort rather well, they incur high levels of prosody loss or are insecure, both of which go against the goals of this work. Efforts to refine techniques like these in order to preserve prosody would be an excellent area of further research.
Here we also include more examples of the "Chicago" utterance with more of the lower-level signals suppressed:
The following WaveSurfer
snapshots show the preservation of prosodic features in the distorted audio
using the custom distortion technique..
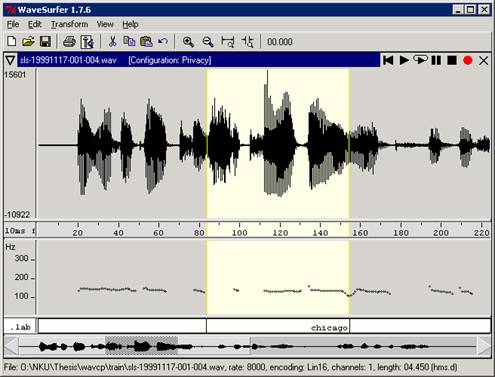
Waveform and Pitch Contour
of Original Audio
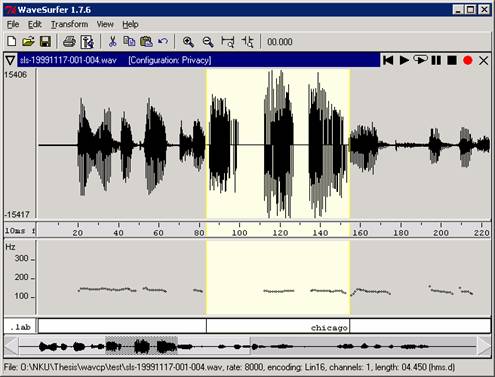
Waveform and Pitch Contour
of Distorted Audio
Praat and WaveSurfer are both used for audio editing and analysis.
CMU Sphinx Group Open Source Speech Recognition Engines used for automated speech recognition.
CMU Sphinx Knowledge Base Tool and CMU Statistical Modeling Toolkit are used for building language models
LDC sph2pipe is used to convert sphere header format audio (.sph) to wav format.
MySQL Open Source Database is used as a relational database.
NIST Spoken Language Technology Evaluation and Utility Speech Recognition Scoring Toolkit (SCTK) is used for calculating word error rates.
ESPS from KTH. ESPS includes the get_f0 program used by compparef0.sh to measure pitch and energy of an audio file.
(see comments in each file for descriptions)
Audio samples from the CU Communicator Corpus used on this site are provided with the written permission of Colorado University - Boulder, CSLR Group, who owns the CU Communicator Corpus.
© 2007, Scot Cunningham